Title here
Summary here
A DS/A interview consists of the following steps:
ALWAYS understand the problem first!
ASK clarification questions!
ALWAYS COMMUNICATE with your interviewer!
When stuck,
Identify which data structures are potentially useful.
 .
.defaultdict(list), defaultdict(set), Counter())The single most powerful trick for any non-specific question is:
Where: bi-directional, often on 1d array/string.
How:
Tips:
| Question | Solution |
|---|---|
| 845. Longest Mountain in Array | Hint: FOR loop; expand both ends. |
| 5. Longest Palindromic Substring | Hint: FOR loop; expand one end first, then expand both ends. |
| 189. Rotate Array | Hint: flip array, then flip both subarrays. |
| 11. Container With Most Water | Hint: only higher heights can lead to higher volume. 1. WHILE loop between l & r. 2. At each step, check if volume needs to be updated. 3. Move the pointer with a smaller height. |
| 75. Sort Colors | Hint: red & blue pointers for reference, white pointer for iteration. 1. r,b to left,right; w for looping from left. 2. If w is 0, swap with r and move both. 3. If w is 2, swap with b and move only b. 4. If w is 1, move w. |
Where: uni-directional, 1d subarray/substring problem
How:
fast for iteration, slow for operation (threshold, comparison, etc.)fast until condition is met.slow until condition is broken.fast until condition is broken.slow.def sliding_window(args):
# Step 1: init
s = 0 # slow pointer
cache = collections.Counter(nums) # cache
# Step 2: iterate
for f in range(len(nums)): # fast pointer
# Step 2.1 expand
cache[f] -= 1
# Step 2.2 shrink
while condition(f): # condition state
cache[s] += 1
s += 1
# Step 3: return whatever the question asks for
return cache[-1]Tips:
| Question | Solution |
|---|---|
| 3. Longest Substring Without Repeating Characters | 1. Expand till f char is already visited. 2. Remove visited s chars till f char is no longer visited. Cache: visited (set), max len (int). |
| 209. Minimum Size Subarray Sum | 1. Expand till curr sum exceeds target. 2. Shrink s till curr sum goes below target again. Cache: curr sum (int), min len (int). |
| 424. Longest Repeating Character Replacement | 1. Expand till curr len >= max char freq + k. Keep track of char counts, max freq, curr len, and max len (i.e., the answer). 2. Shrink s till curr len is smaller again. Update char counts and max freq if necessary. Cache: count (dict), max freq (int), curr len (int), max len (int). |
| 713. Subarray Product Less Than K | 1. Expand & update curr product till it exceeds k. 2. Shrink s till curr product goes below k again. At each step, update #subarrays with the window length. Cache: curr product (int), #subarrays (int). |
| 2302. Count Subarrays With Score Less Than K | 1. Expand till score exceeds k. 2. Shrink s till score goes below k again. At each step, update #subarrays with the window length (window length = #subarrays for the current f pointer.) Cache: curr sum (int), #subarrays (int). |
| 1493. Longest Subarray of 1’s After Deleting One Element | 1. Expand till 0 is met. 2. If first time, update deleted. If not, move s after 0 index. Update 0 index to f in both cases. Cache: deleted (bool), 0 index (int), max len (int). |
| 904. Fruit Into Baskets | 1. Expand till >=2 types of fruits in basket. 2. Move both f & s till only 2 types of fruits in basket. Update window count at each step. Delete the fruit with 0 count. 3. The max length is the window length. Cache: basket (dict). |
| 438. Find All Anagrams in a String | 0. Get p count. 1. Expand till length of p first. 2. Move both f & s. Update window count at each step. Whenever window count is identical to p count, append s to answer. Cache: p count (dict), window count (dict). |
| 76. Minimum Window Substring | 0. Get t count. Init #missing as len(t). 1. Expand till #missing is 0 (i.e., curr window has the substring). 2. Shrink till #missing exceeds 0 again. At each step, we update t count by subtracting f char count (and adding slow char count). We should only update #missing when the counts of t chars (which should always be >=0) change. The trick is, the counts of s chars that are not in t will always be below 0, so they will never affect #missing. Cache: t count (dict), #missing chars (int), min substring indices (int) |
Credits to zhijun_liao and user8301z for helping me understand binary search a lot better.
Where: Find a function that maps elements in the left/right half to True and the other to False.
How: There are 2 cases to consider. (originally 4, but I think 2 are sufficient for explanation.)
# Find First True (i.e., assume `lefts=False, rights=True`)
while l < r:
if condition: r = mid # If True, ans is on the left (inclusive), so we go left.
else: l = mid+1 # If False, ans is on the right, so we go right.
# Find Last True (i.e., assume `lefts=True, rights=False`)
while l < r:
if condition: l = mid # If True, answer is on the right (inclusive), so we go right.
else: r = mid-1 # If not, answer is on the left, so we go left.These 2 templates are easily interchangeable by swapping the condition, so we end up with 1 universal template:
def binary_search(nums) -> int:
def condition(mid) -> bool:
pass
l,r = 0,len(nums)-1 # NOTE: Pay attention to edge cases. Sometimes we need to change this boundary.
while l < r:
mid = l+(r-l)//2
if condition(mid): r = mid
else: l = mid+1
return l| Question | Solution |
|---|---|
| 162. Find Peak Element | Condition: find the first element > its next element. (nums[mid] > nums[mid+1]) |
| 852. Peak Index in a Mountain Array | Condition: find the first element > its next element. (nums[mid] > nums[mid+1]) |
| 153. Find Minimum in Rotated Sorted Array | Condition: find the first element <= everything on its right. (nums[mid] <= nums[r]) |
| 528. Random Pick with Weight | Condition: find the first index with a cumulative probability >= a random probability. (self.w[mid] >= p)NOTE: convert input array to cumulative probabilities. |
| 34. Find First and Last Position of Element in Sorted Array | Condition: find the first element >= input number. (nums[mid] >= n)1. Write this condition in a func. 2. The first occurrence is bs(target). (i.e., first element >= target) 3. The last occurrence is bs(target+1)-1. (i.e., first element >= target+1, then on its left) 4. If first <= last, ans is valid. Else, target not in array. NOTE: given the way last is defined, r=len(nums). |
| 362. Design Hit Counter | Condition: find the index where timestamp-300 would have been inserted at. (self.hits[mid] > target)1. Write this condition in a func. 2. #hits = len(self.hits)-self.bs(timestamp-300). |
| 540. Single Element in a Sorted Array | Condition: find the first element that distorts the duplicate order. - For the input array, if i is odd / i-1 is even, the condition should always hold: nums[i] == nums[i-1].- However, the element we are looking for violates this condition, so we have 2 cases: - if mid is odd and nums[mid] != nums[mid-1].- if mid is even and nums[mid] != nums[mid+1]. |
| 658. Find K Closest Elements | Condition: find the first element that starts the subarray. - Since a is closer than b if |a-x| <= |b-x| and a < b, it is straightforward that our first element in the subarray satisfies |nums[mid]-x| <= |nums[mid+k]-x|.- It’s the same as x-nums[mid] <= nums[mid+k]-x. |
| 719. Find K-th Smallest Pair Distance | Condition: find the smallest distance that has >=k pairs within its range. 1. Write a function that uses two pointers (slow & fast) to find the #pairs with distances <= input distance. Return True if there are >=k pairs, else False. 2. Sort nums for two pointers to work.3. Set r=nums[-1]-nums[0] because our search space is not nums but distances.4. Search. |
Where: interval problems
How: depends on the question tbh.
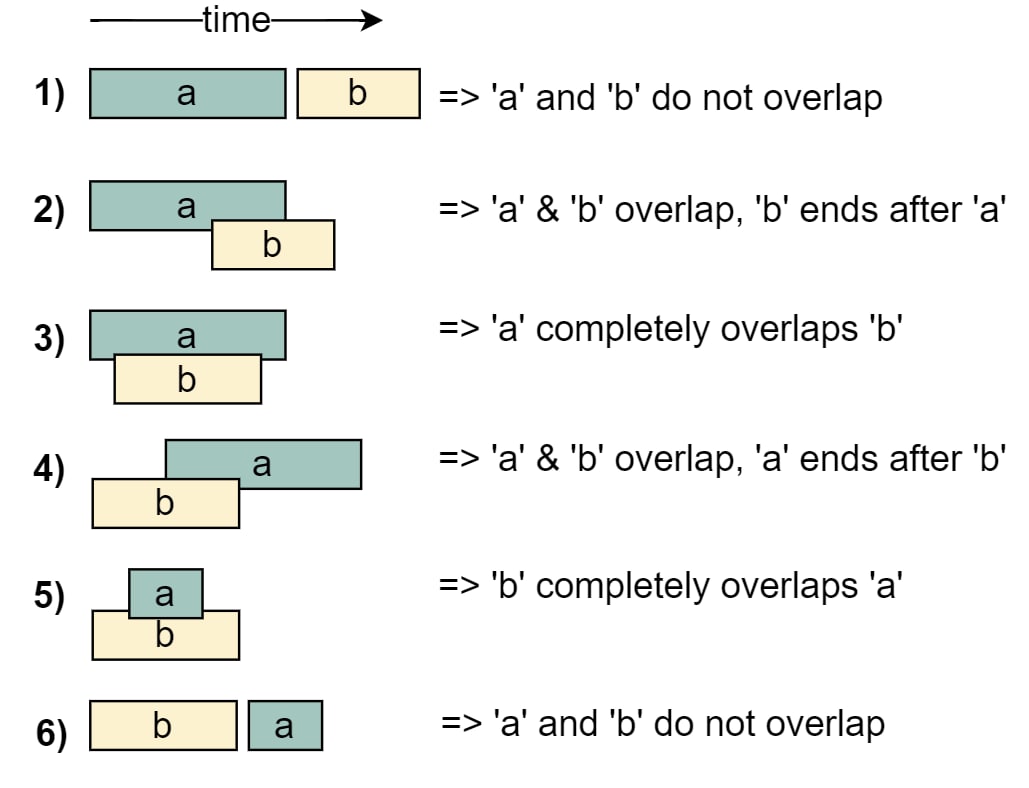
Tips:
start/end.start/end when necessary.| Question | Solution |
|---|---|
| 56. Merge Intervals | 0. Sort. 1. Loop. Append interval till front.end >= back.start.Update front.end with max end. |
| 759. Employee Free Time (opposite of 56) | 0. Flatten & Sort a workhour array by start time. 1. Loop. Append interval till front.end >= back.start.Update front.end with max end.2. Loop through the array of merged workhours. The intervals in between (i.e., [front.end, back.start]) are free hours. |
| 57. Insert Interval | 0. Init left & right subarrays. 1. Loop. Append interval to left if interval.end < newinterval.start (i.e., on the left of new interval)Append interval to right if interval.start > newinterval.end (i.e., on the right of new interval).Else, we find the insertion position. Keep track of the position with MIN of start and MAX of end. 2. Concatenate left, [insert_start, insert_end], and right together as the answer. |
| 986. Interval List Intersections | 0. Init a pointer for each list. 1. Loop till length. If intersect, append [max_start, min_end] to answer (i.e., the intersection interval)Else, move the pointer with the smaller end value. |
Where: The OG problem can be divided into smaller overlapping subproblems with an optimal substructure.
How:
def DP(args):
# Step 1: Init
dp = [0]*(n+1) # DP table
dp[0] = 1 # base case
# Step 2: Iterate
for i in range(1, n+1):
dp[i] = dp[i-1]+1 # state transition
# Step 3: Return end case
return dp[n]| Question | Solution |
|---|---|
| 39. Combination Sum | DP: store the combinations to get the desired amount with the given coins. Base: f(0)=[]; f(coin)=[coin]. Transition: loop through each candidate and all numbers between candidate and target. - If the number is the candidate, store the candidate. - Else, append candidate to all combinations of the previous store. ( dp[i] = dp[i-c]+[c]) |
| 53. Maximum Subarray | DP: store max attainable sum for the given index. Base: all 0. Transition: loop through each index. - If previous max sum is bigger than 0, curr max sum = prev + curr num. - Else, curr max sum = curr num (because adding negative sum is not max.) Return max(dp). |
| 62. Unique Paths | DP: store #unique paths for the given point. Base: set all starting edges to 1. Transition: loop through each point from top left to bottom right. - dp[i][j] = dp[i-1][j] + dp[i][j-1] |
| 139. Word Break | DP: store whether there is a word in worddict that ends with index i in string s. Base: all False. Transition: loop through each index and each word in dict. - If there is such a word and (the preceding word also exists or this word is the first word), then dp[i]=True. |
| 322. Coin Change | DP: store min #coins for each amount till target. Base: f(0)=0; f(coin)=1. Transition: loop through each amount and each coin. - If curr ammount is bigger than the coin, dp[i] = min(dp[i-coin] for coin in coins)+1.- Else, dp[i]=float("inf"). |
| 377. Combination Sum IV | DP: store #combinations for each target till target. Base: f(0)=1. Transition: loop through each target and each number. - dp[i] = sum(dp[i-num] for num in nums) |
| 1143. Longest Common Subsequence | DP: store max common subsequence length for each index in each string. Base: all 0. Transition: loop through each index in each string. - If two chars are the same, dp[i+i][j+1] = dp[i][j]+1- Else, dp[i+1][j+1] = max(dp[i][j+1],dp[i+1][j]) |
| 416. Partition Equal Subset Sum | 2 DPs: both sets store the sums of all subsets till this index. 1 for main store, 1 for looping. Base: f(0)=0. Transition: loop through each index and each stored sum for previous index. 1. Init looping dp. Also, init target sum (i.e., half of total sum). 2. For each stored sum for previous index, stored in the main dp, - At each number, we have 2 options: add it, or don’t. - When add it, we append sum+num to the looping dp.- When don’t, we append sum to the looping dp.- Do both options at each loop because there is no if-else for this problem. 3. Update main dp with looping dp. If target sum in main dp, return True. If no true after all loops, return False. |
| 494. Target Sum | DP: store mappings of “(index, target) -> #ways to get to target from curr index”. DFS: return #ways to get to target from curr index. Leaf case: #ways is either 1 (if hit target) or 0 (if not). Break case: if we already visited (index, target), no need to loop further. Loop: #ways at curr index = #ways at left + #ways at right. Start with (0,0). |
| 329. Longest Increasing Path in a Matrix | DP: store max attainable len for each point. DFS: return max attainable len for curr point. Break case: return 0 if out of boundary or not increasing (keep track of previous number to check if increasing). Loop: if curr point not visited, set curr point store to max of all 4 movements plus 1. Start with all points on matrix. Return the max len. |
My peanut brain literally cannot understand linked list problems, so take this section with a grain of salt.
Where: linked list
Tips:
| Question | Solution |
|---|---|
| 19. Remove Nth Node From End of List | 1. Two pointers at head. 2. Loop fast first till n. If fast cannot reach n, no need to remove.3. Loop both fast and slow. When fast finishes, slow will be at n-1th node.4. Put slow.next to slow.next.next. Return head. |
| 23. Merge k Sorted Lists | 1. Init a dummy node for the later merged list. Init a pointer for the list. 2. Init a heap with first nodes of each list, storing both value and index for the node. 3. Recursively pop & push values and indices to the heap till we run out of nodes. |
| 24. Swap Nodes in Pairs | 1. Init a dummy node for the head. Init 2 pointers (prev & curr) to dummy & head.2. Keep track of 3 nodes in each iteration of the WHILE loop on curr & post.2.1. Point curr & post to new curr & new post. 2.2. Point curr.next to post.next.2.3. Point post.next to curr.2.4. Point prev.next to post.2.5. Move prev to curr. |
Where: increasing/decreasing trend
Tips:
# 739. Daily Temperatures
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
ans = [0]*len(temperatures)
s = [] # store indices of monotonically decreasing temps
for i,t in enumerate(temperatures):
while s and temperatures[s[-1]] < t: # if a higher temp is met
ans[s[-1]] = i-s[-1] # update ans
s.pop() # pop till no higher temp
s.append(i) # append unanswered index to stack
return ans
Where: longest/specific search problems
How?
def dfs_pre(node):
if is_end_case(): return True
if break_condition(): return False
###### ACTION HERE ######
###### ACTION ENDS ######
dfs_pre(node.left)
dfs_pre(node.right)
def dfs_in(node):
if is_end_case(): return True
if break_condition(): return False
dfs_in(node.left)
###### ACTION HERE ######
###### ACTION ENDS ######
dfs_in(node.right)
def dfs_post(node):
if is_end_case(): return True
if break_condition(): return False
dfs_post(node.left)
dfs_post(node.right)
###### ACTION HERE ######
###### ACTION ENDS ######Tips:
Where: shortest search problems
Tips: queue/priority queue
def bfs(node):
if not node: return
q = collections.deque([node])
while q:
node = q.popleft()
###### ACTION HERE ######
###### ACTION ENDS ######
if node.left: q.append(node.left)
if node.right: q.append(node.right)
Where: get min/max fast
| Action | Time |
|---|---|
| top() | O(1) |
| insert() | O(logn) |
| remove() | O(logn) |
| heapify() | O(n) |
Where: scheduling, median, any problem that involves both min and max somehow.
Tips:
# 295. Find Median from Data Stream
class MedianFinder:
def __init__(self):
self.small = [] # heap for the smaller half (negative so that min heap works)
self.large = [] # heap for the larger half
def addNum(self, num: int) -> None: # O(logn)
# It doesn't really matter which one has one more value than the other. But be consistent during interview.
# In this case, we allow "small" to store one more value than "large" when #nums is odd.
if len(self.small)==len(self.large): # if #nums is now even
heapq.heappush(self.small, -heapq.heappushpop(self.large, num)) # push new num to "large", pop the smallest from "large", put it in "small"
else:
heapq.heappush(self.large, -heapq.heappushpop(self.small, -num)) # push new num to "small", pop the largest from "small", put it in "large"
def findMedian(self) -> float: # O(1)
if len(self.small)==len(self.large):
return (self.large[0]-self.small[0])/2
else:
return -self.small[0]
| Algorithm | Time | DS needed |
|---|---|---|
| DFS | O(n) | set (and stack if iteration) |
| BFS | O(n) | set, queue |
| Union-Find | O(nlogn) | array, tree |
| Topological Sort | O(n) | array, set, queue |
| Dijkstra’s Shortest Path | O(ElogV) | set, heap |
| Prim’s MST | O(V
 logV)
logV) | set, heap |
| Kruskal’s MST | O(ElogE) | array, tree |
| Floyd Warshall | O(n
 )
) | matrix |
graph = ...
visited = set()
def dfs_recursive(n):
visited.add(n)
###### ACTION HERE ######
###### ACTION ENDS ######
for neighbor in graph[n]:
if neighbor not in visited:
dfs(neighbor)
def dfs_iterative():
for key in graph: # make sure every node gets a chance (some nodes aren't connected)
if key in visited: continue # prevent cycle
s = collections.deque([key])
while s:
n = s.pop()
visited.add(n)
###### ACTION HERE ######
###### ACTION ENDS ######
for neighbor in graph[n]:
if neighbor not in visited:
s.append(neighbor)
graph = ...
visited = set()
def bfs():
for key in graph: # make sure every node gets a chance (some nodes aren't connected)
if key in visited: continue # prevent cycle
q = collections.deque([key])
while q:
n = q.popleft()
visited.add(key)
###### ACTION HERE ######
###### ACTION ENDS ######
for neighbor in graph[n]:
if neighbor not in visited:
q.append(neighbor)
Where: connected components in undirected graphs
Tips: Don’t forget to UPDATE PARENTS.
parent = [i for i in range(n)]
rank = [1 for _ in range(n)]
def find(x):
"""
If not root, keep finding the root of the curr parent and set it as the new parent.
"""
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
def union(x,y):
"""
If same parent, then they are in the same set already.
If diff parents,
higher rank will be the parent.
if same rank, add one below the other.
"""
rx,ry = find(x),find(y)
if rx == ry: return
if rank[rx] > rank[ry]:
parent[ry] = rx
else:
parent[rx] = ry
if rank[rx] == rank[ry]:
rank[ry] += 1
# update parents once again
parent = [find(i) for i in range(n)]
Where: directed acyclic graphs
Tips:
def topologicalSort(graph):
n = len(graph)
indegree = [0]*n
q = collections.deque()
visited = set()
# if graph is not usable, reformat it
...
# compute indegree
for _,vs in graph.items():
for v in vs:
indegree[v] += 1
# get 0-indegree nodes
for i in range(n):
if indegree[i] == 0:
q.append(i)
# loop queue
while q:
node = q.popleft()
###### ACTION HERE ######
###### ACTION ENDS ######
visited.add(node)
for neighbor in graph[n]:
indegree[neighbor] -= 1
if indegree[neighbor] == 0:
q.append(neighbor)
return
Where: find shortest path from one node to all other nodes
def dijkstra(graph,start,end):
heap = [(0,start)]
visited = set()
# true Dijkstra
while heap:
(p,n) = heapq.heappop(heap) # get node & path
if n == end: return p # return path when found
if n in visited: continue # prevent cycle
visited.add(n) # prevent cycle
for v,w in graph[n]: # check neighbor
heapq.heappush(heap,(p+w,v))
return -1
Where: find shortest path from all nodes to all other nodes
def floyd_warshall(graph):
# init
N = len(graph)
dist = [[float("inf")]*N for _ in range(N)]
# set it identical as graph
for i in range(N):
for j in range(N):
dist[i][j] = graph[i][j] # assume graph is 2d matrix
# true Floyd Warshall
for k in range(N): # intermediate node
for i in range(N): # start node
for j in range(N): # end node
dist[i][j] = min(dist[i][j], dist[i][k]+dist[k][j]) # the triangle rule
return dist
Where: find MST with given node
def primsMST(graph):
ans = 0
visited = set()
heap = [(0,0)] # (edge,node)
# true Prim
while len(visited) < len(graph): # #edges should not exceed #nodes
e,n = heapq.heappop(heap) # get node & edge
if n in visited: continue # prevent cycle
ans += e # add edge to ans
visited.add(node) # prevent cycle
for new_e,new_n in graph[n]: # check neighbor
if new_n not in visited:
heapq.heappush(heap, [new_e,new_n])
return ans
Where: find MST with nothing
def KruskalMST(graph):
MST = []
parent = [i for i in range(n)]
rank = [1 for _ in range(n)]
i = 0 # index for sorted edges in graph
# sort graph by edge weight
graph = sorted(graph, key=lambda x:x[1])
# true Kruskal
while len(MST) < len(graph)-1: # #edges should not exceed #nodes
u,w,v = graph[i] # get nodes & edge
x,y = find(u),find(v) # get parents
if x != y: # prevent cycle
MST.append([u,w,v]) # append to MST
union(x,y) # now they are connected
i += 1 # on to the next edge in graph