Language Models
For consistency, notations strictly follow the original papers.
PLMs
This section includes basic transformer-based LM structures that are still widely used when LLMs are unavailable.
GPT#
Ref: Generative Pre-Training
Ideas:
- transformer decoders only
- unsupervised pretraining on a diverse unlabeled corpus
- supervised finetuning on each specific task
- (in practice) [EOS] token as separator
Unsupervised pretraining:
- Objective: Autoregressive MLE on tokens
$$
L_1(\mathcal{U})=\sum_i\log P(u_i|u_{i-k},\cdots,u_{i-1};\Theta)
$$
 : unlabeled corpus
: unlabeled corpus : context window size
: context window size : param set
: param set
- Structure: Transformer decoders

 : token embedding matrix
: token embedding matrix : position embedding matrix
: position embedding matrix : context vector of tokens
: context vector of tokens : #layers
: #layers
Supervised finetuning:
- Objective (basic): depends on the specific task, generally MLE if discriminative
$$
L_2(\mathcal{C})=\sum_{(x,y)}\log P(y|x^1,\cdots,x^m)
$$
 : labeled dataset
: labeled dataset : seq of input tokens
: seq of input tokens : label
: label
- Objective (hybrid): include LM as auxiliary objective
$$
L_3(\mathcal{C})=L_2(\mathcal{C})+\lambda L_1(\mathcal{C})
$$
 : weight
: weight- Pros:
- improve generalization of supervised model
- accelerate convergence
GPT-2#
Ref: GPT-2
Ideas:
- Larger (#params: 1.5B > 117M)
- More diverse data
- Task-agnostic: learn supervised downstream tasks without explicit supervision
- Zero-shot capability
GPT-3#
Ref: GPT-3
Ideas:
- Even larger (#params: 175B > 1.5B)
- Even more diverse data
- Even more task-agnostic
- Few-shot capability
- Prompting
BERT#
Ref: Bidirectional Encoder Representations from Transformers
Ideas:
- transformer encoders only
- bidirectional context in pretraining
- (in practice) [CLS] token first, [SEP] token as separator
Input representation:
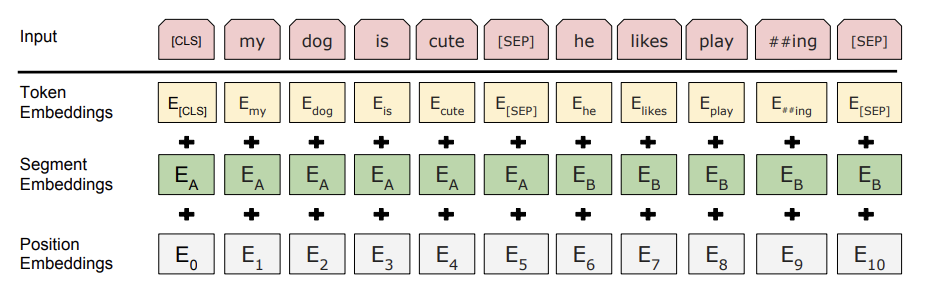
Unsupervised pretraining:
- Masked Language Modeling (MLM): randomly mask some words (15% in original experiment) and predict them.
- Problem: [MASK] token does not exist in downstream tasks
- Solution: further randomness - if a token is chosen to be masked, replace with
- [MASK] 80% of the time
- random token 10% of the time
- itself 10% of the time
- Next Sentence Prediction (NSP): predict whether sentence
 , in order to understand relationships between sentences.
, in order to understand relationships between sentences.- When selecting training samples,
- 50% of the time
 ’s next sentence, labeled as
’s next sentence, labeled as IsNext. - 50% of the time
 ’s next sentence, labeled as
’s next sentence, labeled as NotNext. - Predict on [CLS] head.
RoBERTa#
Ref: Robustly Optimized BERT Approach
Ideas:
- Enhanced BERT pretraining:
- Dynamic masking: generate masking when feeding a seq to the model, instead of using same masking from data processing.
- Remove NSP: remove NSP loss + use
FULL-SENTENCES (packing seqs from multiple docs) - Large mini-batches:
LLMs
This section includes the widely used LLMs on the market.
GPT-3.5#
GPT-4#
Google#
LaMDA#
PaLM#
OPT#
LLaMA#